
Comment le moteur sql server organise leurs indépendances l’un de l’autre
Le commit et le checkpoint sont deux notions primordiales dans les systèmes de gestion de bases de données. L’un valide les données et l’autre les rends persistants pas leurs écritures sur le disque. Ces notions semblent se confondre mais elles sont bien indépendantes l’une de l’autre et leurs rôles bien distincts.
- Le commit valide la transaction. C’est à dire que quelque soit le niveau d’isolation utilisé les données concernées sont à disposition de requêtes tiers, en lecture, mise à jour ou suppression.
- Le checkpoint lance l’écriture des pages contenant les données modifiées sur le disque, c’est à dire sur le fichier data de la base de données. Les pages concernées sont, avant cette étape, encore en mémoire.
Ci-dessous le schéma décrivant le parcours de données modifiées. J’entends par là les données mises à jour, insérées ou supprimées.
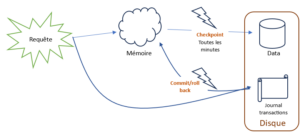
Lors de la requête de mise à jour; les pages, chargées en mémoire au préalable, sont modifiées et les informations concernant cette évolution sont écrites dans le journal de transactions, dans le même temps.
C’est après cette étape qu’interviennent le commit et le checkpoint.
Ces deux actions semblent, instinctivement, inconciliable, alors comment le moteur SQL Server les fait cohabiter ? Nous allons tenter d’y répondre à l’aide des réflexions ci-dessous.
- Mais si le commit et le checkpoint sont exécutés indépendamment l’un de l’autre, ça veut dire que les données modifiées peuvent être écrites sur le disque (dans le fichier de données) et donc lisible/validée avant qu’elles aient été commitées ?
- Oui, elles peuvent être écrites sur le disque avant d’avoir été commitées (dans le cadre d’un open transaction et/ou après avoir été écrites dans le journal de transactions) mais elle ne seront accessibles qu’en fonction du niveau d’isolation activé. Par défaut, sur une instance on promise, celui-ci est read committed, c’est-à-dire qu’il ne laisse l’accès qu’aux données déjà commitées.
- Mais on écrit sur le disque (sur le journal de transactions) avant de provoquer un commit ? Alors que les données sont écrites en mémoire pour justement éviter l’écriture sur le disque. Cette dernière action est connue pour être bien trop chronophage.
- L’écriture sur le journal de transactions est incrémentale, elle est plus rapide que l’écriture sur LA page concernée par la donnée modifiée qui, elle, doit trouver et atteindre le secteur du disque concerné, ce qui est plus long.
Laisser un commentaire